书接上文 - Multi Paxos
在上一篇文章中,我们提到了Basic Paxos和Multi Paxos的异同。在Paxos Made Simple论文中,作者提到了Multi Paxos的一种实现。这个实现允许我们对一个连续的数据流(也可以称为复制日志,replicated log)达成共识,从而实现节点状态的一致性复制。
确定性状态机
我们可以将系统中的每一个节点抽象为一个有着确定性状态机,即给定多个状态一致的状态机,在执行同一个命令之后,其状态仍保持一致。(可以想一想编译原理里面的DFA)
Leader - 系统中唯一的proposer
如果系统中存在有多个proposer,那么就很可能会出现多个提案相互干扰的情况。虽然根据证明,最终这些提案都会收敛到一致,但是性能会非常低下。所以我们可以在系统中通过选举,选出一个leader做为主proposer(distinguishied proposer),所有的提案都由leader提出。
这样一来,在绝大多数情况下都不会出现提案相互干扰的情况。只有在leader切换的瞬间,可能会出现相同编号的不同提案,但是我们的算法可以很好的处理这种情况。
分布式系统中的“TCP”
类似于TCP协议中序列号,Multi Paxos中的每一个命令都有一个递增的编号。即我们前一个执行的命令是100号,那么下一个执行的命令一定是101号。每一个命令都是一个Paxos实例,Leader向所有节点发布这个提案,在提案达成一致之后(多数节点返回ACK),就可以认为这个命令已经达成了一致。
和TCP一样,如果我们顺序的发布并表决提案,效率会非常低下(TCP停等模型)。所以,Multi Paxos采用类似滑动窗口的方案,每次对N个提案进行表决,以增加表决的带宽。
和TCP不同的是,如果某些序号的TCP包在传输中丢失,最坏的情况是我们会RST这条链接,其它的工作都交给应用层逻辑来解决。
但是对于Multi Paxos来说,如果某些提案没有被表决,那么就会在日志中留下空洞(gap)。这会直接影响系统的一致性。如果恰巧这个时候发生了Leader失效,那么新选举出来的Leader节点就要处理日志中的空洞。
解决空洞的原理也很简单,就是Leader向所有成员询问,对于这个提案,是否已经有达成共识的值。如果有的话,就使用这个值。如果没有,就用一个no-op(无操作)命令来填补这个空位。但是,对于实际工程中来说,我们还需要解决未达成共识时值的冲突等情况。
为什么我们还需要Raft?
Multi-Paxos在现实的工程当中更多的是一种符号。因为理论与实践上的隔阂是如此之大,如果想在工程意义上实现一个可用的Multi-Paxos算法,必然会在原算法的基础上进行一系列的魔改,这些魔改虽然均声称自己实现了Multi-Paxos算法,但是这些算法大多不能被证明是正确的。
Raft的目标是,即让算法满足工程化需要,又能保证其正确性。
Raft论文当中说Paxos算法难以理解,我并不这么觉得。因为Paxos论文里面把困难的部分都一笔带过了。只剩下简单的那部分了。
Raft vs. Paxos
Leader选举
在Paxos论文中,Leader选举被视作一种特殊的“提案选举”。只需要Proposer和Acceptor进行一轮或多轮(取决于运气)投票,就可以确定Leader。
但在实际工程中,我们需要考虑以下的问题:
-
如何判断Leader是否存活
-
是否每一个节点都有资格担当Leader
Leader的任期
Leader在被选举出来之后,都会被赋予一个任期编号(term)。在任期里,Leader会向所有成员发送心跳包以延续自己的任期。
如果Leader失效无法发送心跳包的话,成员就会产生一个“选举超时”,此时就会重新触发一轮选举。
选举的流程和Basic-Paxos算法类似,proposer向所有成员发送“我要当老大”的提案,成员们会酌情回复。如果得到了多数成员的肯定,这个proposer就是下一个任期的Leader了。
从本质上说,每一个任期的Leader选举,都是一个独立的Basic-Paxos实例。任期号相当于Paxos里面的提案编号。
Leader资格的认定
Raft采用强一致性的模型,对于已经ACK的用户请求,要尽力保证其状态不丢失。
如果你问我,现在来一核弹把机房炸了,数据都丢了,那你怎么能保证强一致性。
其实这个问题非常简单。很明显,我们保证了丢数据的强一致性。
所以我们要选出一个Leader,使其能够包含所有已经ACK的提案。当一个proposer向其它节点发送提案时,就会收到其它节点的响应。因为一个已经ACK的提案必然被多数节点所认可,所以如果一个proposer没有包含所有被ACK的提案时,它的提案就会被其它包含更多状态的节点驳回。最后被选出来的Leader,一定是包含所有被ACK的状态的节点。
日志复制
当Leader被选出后,Leader就会开始处理用户的请求。用户的请求可以看做一系列的命令,在接收到提案后,提案首先被分发到所有节点,节点的状态机顺序执行这些命令。在多数节点返回ACK后,这个命令就被视为“已提交”(commited)。
上文中已经提到了一致性算法中的日志非常类似于网络协议中的TCP。即如果两个命令的ID一样,那么其内容必定也一样;如果两个节点都有认可了编号为p的命令,那么所有编号小于p的命令也必定保持一致。(被称为Log Matching Property)
Raft为了简化算法的工程实现,把节点的状态抽象为严格append only的日志。即我们可以将日志指针向后或向前移动,来“回滚”或“更新”状态。但是绝对不允许在日志中间添加或删除日志条目。所以,在Leader发生变化时,如果leader和其他follower之间的日志不同,那么follower需要回滚日志以保持和leader日志的一致性。
安全性
不归我管的事我不拿主意
前文我们说到,一个节点要成为Leader,一定要拥有所有已经被ACK的状态,否则就会被其它节点驳回。
但是现实都会出现一些小小的意外。在系统的运行过程中,如果有一些提案只被少数节点认可,与此同时发起提案的Leader意外退出。那么在不同节点上的日志会产生“分叉”,那么我们如何解决日志当中的冲突呢?
很明显,因为这些以少数节点认可的提案并没有被确认。所以我们无论是接受提案还是驳回提案,都不影响我们强一致性的要求。所以关键是处理冲突,使其不产生影响系统一致性的后效。
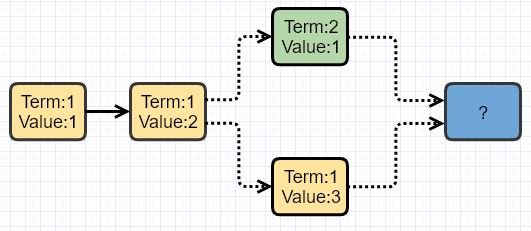
假设在Term1,最后一个提案是”Value:3”,这个提案并没有得到多数节点的认可,Leader就挂掉了。选出来了一个新Leader,Term数加1。在Term2,被提出的第一个提案是”Value:1”,这个提案也没有得到多数节点的认可,Leader也挂掉了。
因为这两个分叉的提案都没有得到多数节点的认可,所以下一个Leader可能已经确认这两个提案,或者两个中的一个,也可能一个都没有确认。新的Leader在被选出后,需要面对的第一个问题是如何处理属于旧Term的提案。
解决方案有两种:
- 新Leader将日志中仍没有被多数节点认可的提案重新提出,直到被多数节点认可为止
- 新Leader忽略属于旧的Term的提案,只提交属于本Term的提案;对于日志冲突,使用复制日志的方法解决,但不会显式认可旧Term的提案。
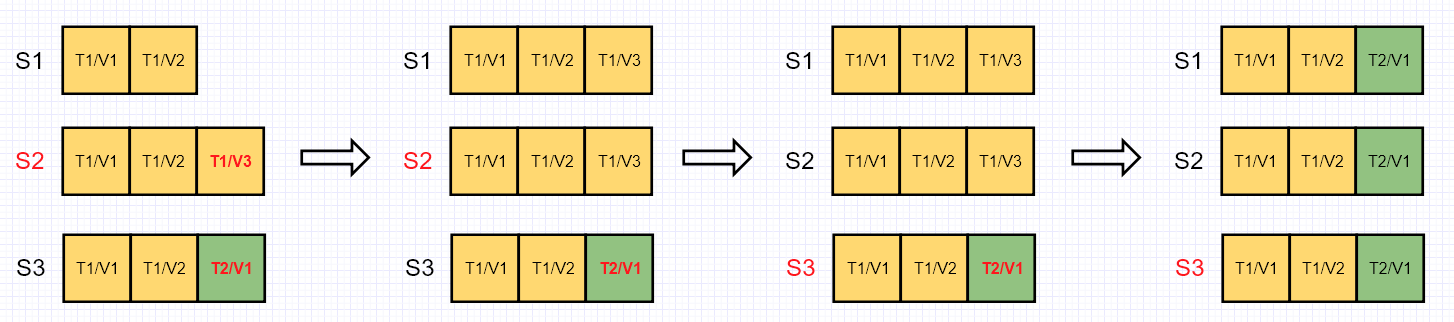
对于方案1,有一个隐含的问题。如上图所示,在时间点1,S2为Leader,标红的两个提案并没有被确认。此时如果Leader在时间点2重新提出”Term1/Value3”,并且得到了S1和S2的认可,那么这条提案已经被多数节点认可。但是在时间点3,S3被选举为了Leader。S1和S2需要回滚日志以保持与S3日志的一致。此时就出现了一种情况,那就是已经被确认的日志被回滚掉了,强一致性就不能满足了。
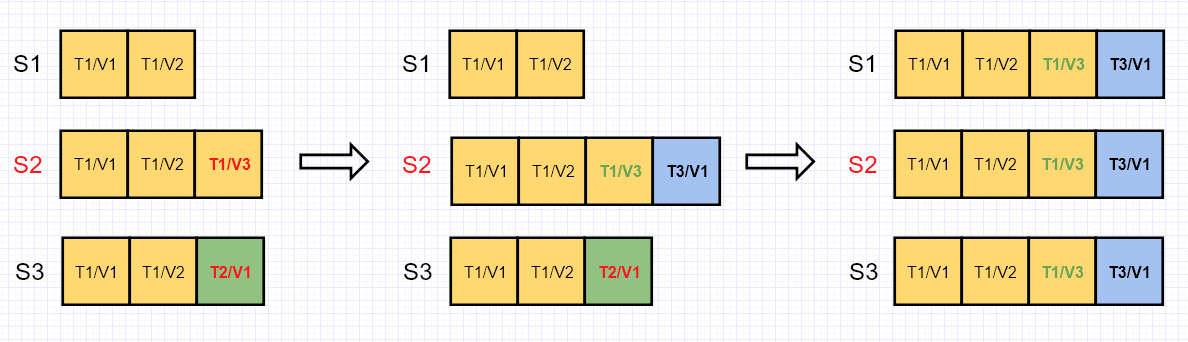
如果我们采用方案2,那么被选出的新Leader提出的第一个提案的Term一定为3。确认新提案的节点接下来会复制Leader的日志,回滚掉没有被认可的提案”Term2/Value1”。对于标绿的”Term1/Value3”,虽然被复制到了其它的节点上,但是这个值并不会被确认。这样一来,我们既保证了已经被确认的提案不会被回滚,又保证了日志的一致性。
在具体实现中,“T3/V1”往往是一个空命令(no-op)。这样一来,即使没有写请求,Leader就可以更快的确认新的任期并同步Log了。
如何证明
那么怎么保证上面的作法它是正确的呢?
假设当前任期为T1,此时由于系统故障,我们选出了新的Leader - S2,并记Term为T2。因为我们严格遵守了Log Matching Property。
那么,对于以下两种情况:
- T2的Leader和Voter的Log中最后一个提案的编号是一致的,那么可以知道他们日志中的提案都是完全一致的
- T2中Leader的Log比Voter更新,那么Leader一定包含比Voter更多的提案;否则Voter就不会给Leader投票
我们都可以证明,对于前一个Term已经被确认的提案,一定会被包含在后一个Term的日志中。也就是说,一个被确认的提案不会中途丢失。
成员变化
以上我们的讨论都基于系统的节点不会发生变更,但是在现实工程中,我们很难对此进行任何保证。所以一个实用的系统,一定能解决成员变化的问题。
成员变化问题的本质是系统中不能同时出现两个Leader。
在Raft中,我们将过渡期的配置称为“共同一致”(joint consensus),一但它被确认,说明系统已经过渡到了新的成员配置。
具体的策略如下:
- 系统中只有旧的配置C_old,新加入的成员不可能成为Leader
- 当前系统的Leader接受到新的配置C_new。然后Leader向所有节点发起修改配置为C_old+new的提案。
- 即使这个时间点Leader挂掉了,新的Leader也只会拥有旧配置C_old或者过渡期配置C_old+new。这取决于Leader选举的时机(和运气)。
- 当过渡期配置C_old+new被多数节点确认后,Leader向所有节点发起修改配置为C_new的提案。
- 如果这个时间点Leader挂掉了,新Leader会从拥有C_old+new和C_new的节点中选出。新的Leader仍然可以进行配置的变更,而不影响整个系统的安全性。
- 直到C_new被确认,配置更换宣告完成。
“共同一致”允许节点无需考虑安全性的情况下,在任意时间进行配置的更换。配置的更换也不会影响客户端的请求。
以上我们解决的是安全性问题,但是在实际工程中我们还需要兼顾效率问题。
例如新加入的节点可以视作“non-voting members”,只同步数据,不能对提案进行投票。直到数据同步基本完成,才进行配置变更。这样避免了新的节点由于缺少Log不能及时的处理提案。
又如新的成员列表中,不包含原先的Leader节点。在旧Leader认可了新的配置提案之后,就可以退位让贤,让其它节点选举出新的Leader。
以及被清除出成员列表的节点,不会收到后续的心跳,它们会认为Leader已经失效,所以自己跳出来竞选Leader。这样一来,就会触发新的(无意义 的)Leader选举,影响系统的可用性。解决方案是,如果一个节点在一个时间段内收到了Leader的心跳,那么就会忽略Leader的竞选请求。这样既不会影响正常的选举,又可以屏蔽无效的选举请求。
快照
我们的提案越来越多,日志也越来越长。随之而来的是漫长的恢复时间以及磁盘空间的浪费。快照技术可以帮我们清除旧的无用日志,只保留有用的状态信息。
在Raft算法中,每个节点都能自主的生成快照。好处是避免Leader分发快照造成的效率降低,也简化了Leader的功能和职责。又由于日志的“TCP特性”,所以不同节点上,只要保证提案编号一致,那么其内容就可以保证一致。
客户端交互
由于客户端不了解系统内部的选举情况,所以在开始通信时,会随机选一台节点发送请求。如果这个节点不是Leader,就会拒绝这个请求,会告知客户端哪个节点是当前任期的Leader。如果Leader失效,客户端请求超时,就会重新随机选择节点,获取新任Leader信息。
对于客户端发送的写请求,Leader需要记录其唯一的请求ID,以避免客户端发送的重复请求。
对于客户端发送的读请求,Leader需要再次确认它是仍是当前任期的Leader,避免向客户端发送过期数据。如果对数据正确性和时效性的敏感性不高,就可以向系统中的任意节点发送请求,
写在后面
Paxos的亮点在于把复杂的东西说简单了。而Raft的亮点是把简单的东西具体化,使之成为能落地的工程项目。
但是Paxos做为一种Quorum协议(俗称P2P),其工程复杂性是难以避免的。Raft在Paxos协议上面加入了很多限制以简化实现,但是想要完整的实现其功能仍不是一件容易的事。(有兴趣的同学可以挑战一下自己)
下面一篇文章我们会换一种新思路,学习PecificA算法,看一看如何使用Paxos实现一个主从复制协议。
写在更后面
个人觉得,Raft论文的一个更大亮点是充分的思考了Paxos/Multi-Paxos在工程实践上的缺陷。思考并提出有价值的质疑,而不是被他人的观点带着走,真的是最重要的能力之一了。
大胆猜测是因为有足够的理解能力,有额外的带宽去发问?这是一个有意思的问题。
Comments
comments powered by Disqus